



近日,由IEEE计算智能学会(CIS)和国际神经网络学会(INNS)联合主办的顶级旗舰会议——国际神经网络联合会议(International Joint Conference on Neural Networks,IJCNN)正式录用中国移动杭州研发中心的学术论文《RIFE-AOV: An Efficient Real-time Video Frame Interpolation Method for Always-on Video》(在线视频光流估计:一种面向在线视频的高效实时光流估计方法)。该论文提出的在线视频光流估计增强(RIFE-AOV)框架,显著提升了视频编码过程中的时序连续性与视觉质量。
当前,实时光流估计技术在智能安防、智慧城市等领域具有重要应用价值。但业界通用方法普遍存在两大核心缺陷:
一是光流估计网络处理“时间间隔较长”的场景时能力不足,主流光流估计网络(如RIFE)针对高帧率、密集采样场景设计,相当于一套适配“高速连拍”的算法模型,而当设备处于低帧率状态时,帧间时间间隔长、运动不确定性大,原有模型与这类长间隔、低帧率场景不匹配,难以精准还原复杂运动与细节信息。
二是特征建模“重局部、轻结构”问题突出,现有轻量化网络多依赖局部卷积进行特征提取,缺乏对全局上下文与运动边界方向性的建模能力,比如我们只注重一幅画的局部细节,不关注整幅画的布局和线条走向,就会导致优化后的画面运动边界模糊不清、整体结构变形,还会出现一些多余的、不自然的痕迹(伪影)。
针对以上挑战,中国移动杭州研发中心视联网团队创新性提出RIFE‑AOV框架。其核心思路是将全局方向感知注意力机制(GDAM)融入光流估计与特征建模过程,为模型构建一套兼具“全局感知+精准聚焦”的增强机制。
在通道维度,设计全局通道注意力(GCA),使模型自动聚焦与物体运动、图像结构相关的关键特征,有效缓解因长时间间隔带来的信息丢失问题。
在空间维度,引入方向感知空间注意力(DSA),强化模型对运动边界与梯度方向的感知能力,显著改善边界模糊、结构错乱等现象。
团队将上述两种机制融合为全局方向感知注意力机制(GDAM),并嵌入至IFNet的核心模块IFBlock中,实现对运动特征的全局增强与结构信息的精细化建模,大幅提升低帧率转高帧率场景下的视频编码效果。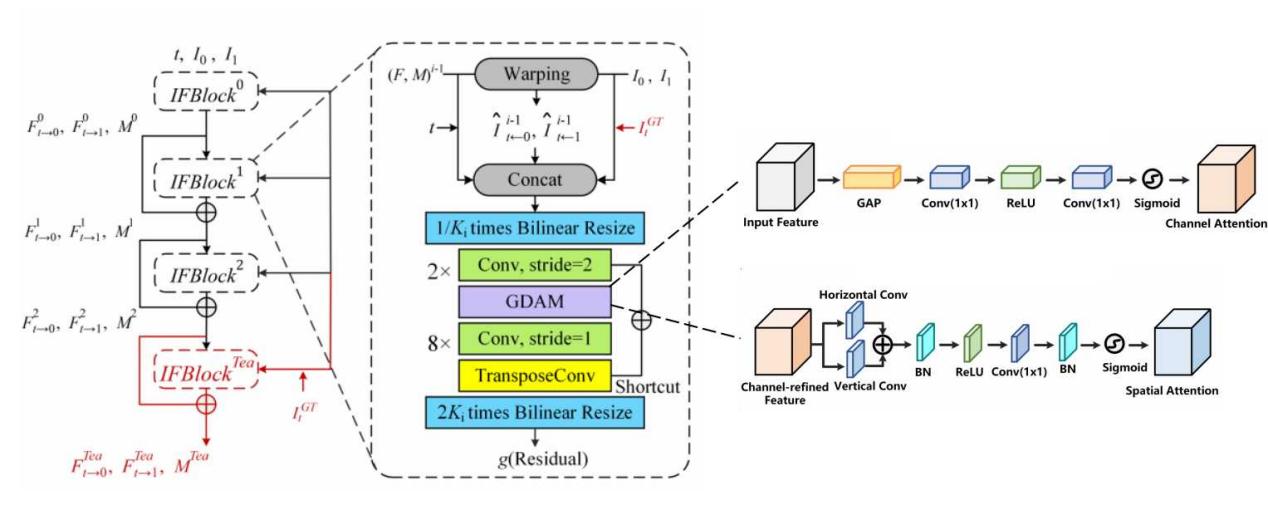
本项工作由中国移动杭州研发中心自主研发,被国际神经网络联合会议IJCNN录用。该会议是全球领先的计算智能领域综合性学术大会(IEEE World Congress on Computational Intelligence,WCCI)的顶级旗舰会议。自1987年首次举办以来,该会议已成为神经网络领域的国际顶尖学术平台,专注于发表神经网络理论、算法、模型与应用方面的前沿研究成果。此次论文的成功录用,标志着中国移动杭州研发中心在神经网络与视联网交叉领域的创新研究达到国际先进水平,不断积累视联网与人工智能交叉领域的核心技术能力,筑牢自主可控的技术基座。未来,将持续聚焦深度神经网络在视频编解码效率优化、画质提升中的创新应用,推动视联网内容呈现从平面向立体升级,实现更具沉浸感、交互性的视联网服务。(陈鑫/文 中国移动杭州研发中心/供图)